A Framework for Meaning Stability in Human–Machine Teams

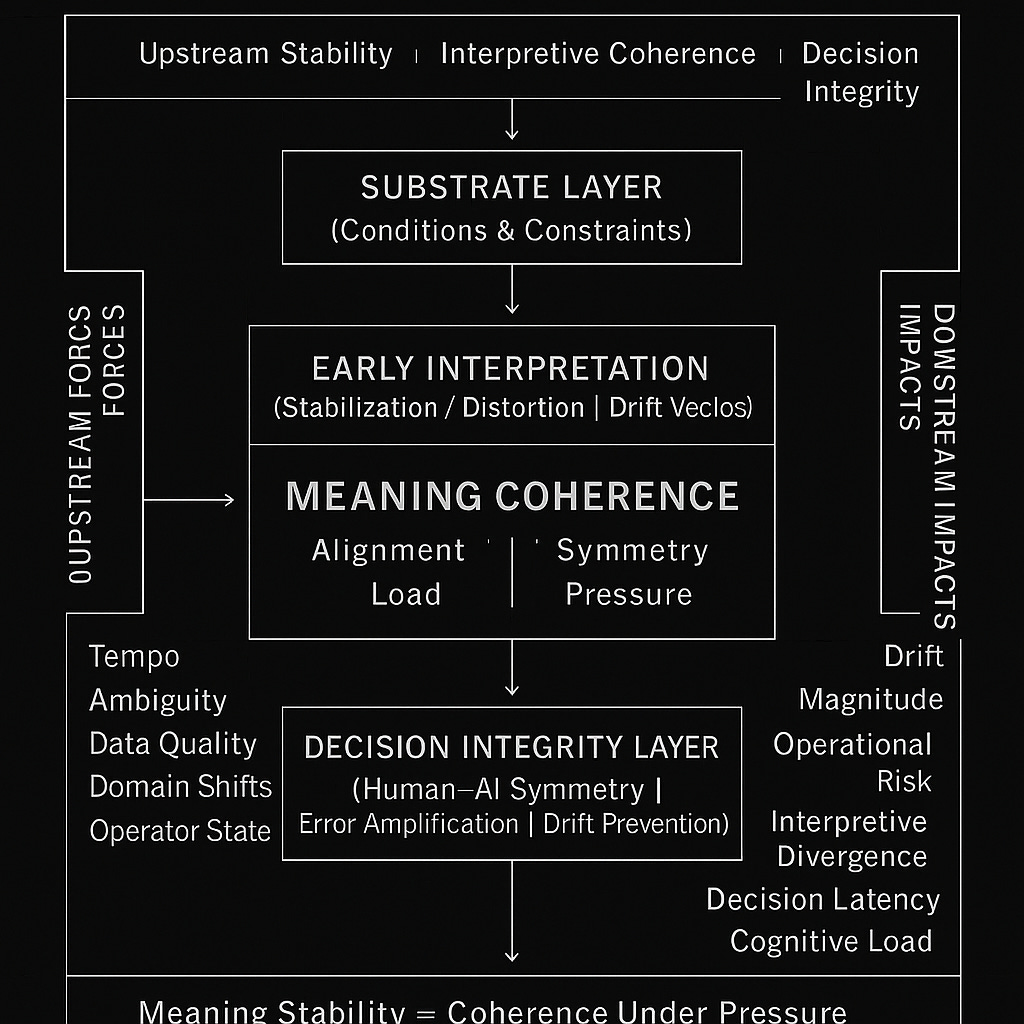
For the past several months, I’ve been mapping a pattern I kept seeing across AI-enabled operations, joint exercises, ISR workflows, model failure analyses, and human–machine teaming research:
Systems weren’t failing because the models were wrong.
They were failing because meaning was drifting upstream.
Small shifts in the substrate layer.
Frame-mismatch under load.
Human–AI divergence that wasn’t visible until it was too late.
Adversaries shaping context long before a system ever produced an output.
It became clear that we don’t have a technical problem -
we have a meaning integrity problem.
Today I’m releasing a full doctrine paper that formalizes the framework behind that insight:
The Cognitive Integrity Doctrine:
Operational Framework for Meaning Stability in Human–Machine Teams
This paper introduces three operational tools:
• CLCP - Cognitive Load Collapse Predictor
• AMIM - Adversarial Meaning Injection Map
• HACSI - Human–AI Coherence Synchronization Index
Together, they define the architecture, metrics, and defensive posture required to stabilize the interpretive layer of modern operations - the layer every decision depends on, and the one we currently leave undefended.
My goal isn’t to add noise to an already noisy space.
My goal is to put structure around a vulnerability that has remained unarticulated for too long:
Meaning is now a battlespace.
Cognitive Integrity is how we defend it.
The full paper is below - I hope it contributes something useful to the operational, technical, and doctrinal communities who have been wrestling with these challenges in real time.
If this resonates with you - whether you’re working in AI, defense, cognition, decision science, or operational design - I’d love to hear your perspective.
We’re all trying to solve the same problem:
How do we keep meaning stable when the battlespace is shifting beneath our feet?